Ted Cole Ted Cole
0 Course Enrolled • 0 Course CompletedBiography
100% Pass Quiz Professional Google - Professional-Machine-Learning-Engineer - Google Professional Machine Learning Engineer Study Demo
PrepPDF has formulated Professional-Machine-Learning-Engineer PDF questions for the convenience of Google Professional-Machine-Learning-Engineer test takers. This format follows the content of the Google Professional-Machine-Learning-Engineer examination. You can read Google Professional-Machine-Learning-Engineer Exam Questions without the limitations of time and place. There is also a feature to print out Google Professional-Machine-Learning-Engineer exam questions.
PrepPDF is a reputable platform that has been providing valid, real, updated, and free Google Professional Machine Learning Engineer Professional-Machine-Learning-Engineer Exam Questions for many years. PrepPDF is now the customer's first choice and has the best reputation in the market. Google Professional-Machine-Learning-Engineer Actual Dumps are created by experienced and certified professionals to provide you with everything you need to learn, prepare for, and pass the difficult Google Professional-Machine-Learning-Engineer exam on your first try.
>> Professional-Machine-Learning-Engineer Study Demo <<
Professional-Machine-Learning-Engineer Study Demo 100% Pass | High Pass-Rate Google Google Professional Machine Learning Engineer Actualtest Pass for sure
IT exam become more important than ever in today's highly competitive world, these things mean a different future. Google Professional-Machine-Learning-Engineer exam will be a milestone in your career, and may dig into new opportunities, but how do you pass Google Professional-Machine-Learning-Engineer Exam? Do not worry, help is at hand, with PrepPDF you no longer need to be afraid. PrepPDF Google Professional-Machine-Learning-Engineer exam questions and answers is the pioneer in exam preparation.
Google Professional Machine Learning Engineer Sample Questions (Q257-Q262):
NEW QUESTION # 257
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this:
A)
B)
C)
D)
- A. Option C
- B. Option B
- C. Option A
- D. Option D
Answer: A
NEW QUESTION # 258
You are developing an image recognition model using PyTorch based on ResNet50 architecture. Your code is working fine on your local laptop on a small subsample. Your full dataset has 200k labeled images You want to quickly scale your training workload while minimizing cost. You plan to use 4 V100 GPUs. What should you do? (Choose Correct Answer and Give References and Explanation)
- A. Create a Google Kubernetes Engine cluster with a node pool that has 4 V100 GPUs Prepare and submit a TFJob operator to this node pool.
- B. Configure a Compute Engine VM with all the dependencies that launches the training Train your model with Vertex Al using a custom tier that contains the required GPUs.
- C. Create a Vertex Al Workbench user-managed notebooks instance with 4 V100 GPUs, and use it to train your model
- D. Package your code with Setuptools. and use a pre-built container Train your model with Vertex Al using a custom tier that contains the required GPUs.
Answer: D
Explanation:
The best option for scaling the training workload while minimizing cost is to package the code with Setuptools, and use a pre-built container. Train the model with Vertex AI using a custom tier that contains the required GPUs. This option has the following advantages:
* It allows the code to be easily packaged and deployed, as Setuptools is a Python tool that helps to create and distribute Python packages, and pre-built containers are Docker images that contain all the dependencies and libraries needed to run the code. By packaging thecode with Setuptools, and using a pre-built container, you can avoid the hassle and complexity of building and maintaining your own custom container, and ensure the compatibility and portability of your code across different environments.
* It leverages the scalability and performance of Vertex AI, which is a fully managed service that provides various tools and features for machine learning, such as training, tuning, serving, and monitoring. By training the model with Vertex AI, you can take advantage of the distributed and parallel training capabilities of Vertex AI, which can speed up the training process and improve the model quality.
Vertex AI also supports various frameworks and models, such as PyTorch and ResNet50, and allows you to use custom containers and custom tiers to customize your training configuration and resources.
* It reduces the cost and complexity of the training process, as Vertex AI allows you to use a custom tier that contains the required GPUs, which can optimize the resource utilization and allocation for your training job. By using a custom tier that contains 4 V100 GPUs, you can match the number and type of GPUs that you plan to use for your training job, and avoid paying for unnecessary or underutilized resources. Vertex AI also offers various pricing options and discounts, such as per-second billing, sustained use discounts, and preemptible VMs, that can lower the cost of the training process.
The other options are less optimal for the following reasons:
* Option A: Configuring a Compute Engine VM with all the dependencies that launches the training.
Train the model with Vertex AI using a custom tier that contains the required GPUs, introduces additional complexity and overhead. This option requires creating and managing a Compute Engine VM, which is a virtual machine that runs on Google Cloud. However, using a Compute Engine VM to launch the training may not be necessary or efficient, as it requires installing and configuring all the dependencies and libraries needed to run the code, and maintaining and updating the VM. Moreover, using a Compute Engine VM to launch the training may incur additional cost and latency, as it requires paying for the VM usage and transferring the data and the code between the VM and Vertex AI.
* Option C: Creating a Vertex AI Workbench user-managed notebooks instance with 4 V100 GPUs, and using it to train the model, introduces additional cost and risk. This option requires creating and managing a Vertex AI Workbench user-managed notebooks instance, which is a service that allows you to create and run Jupyter notebooks on Google Cloud. However, using a Vertex AI Workbench user-managed notebooks instance to train the model may not be optimal or secure, as it requires paying for the notebooks instance usage, which can be expensive and wasteful, especially if the notebooks instance is not used for other purposes. Moreover, using a Vertex AI Workbench user-managed notebooks instance to train the model may expose the model and the data to potential security or privacy issues, as the notebooks instance is not fully managed by Google Cloud, and may be accessed or modified by unauthorized users or malicious actors.
* Option D: Creating a Google Kubernetes Engine cluster with a node pool that has 4 V100 GPUs.
Prepare and submit a TFJob operator to this node pool, introduces additional complexity and cost. This option requires creating and managing a Google Kubernetes Engine cluster, which is a fully managed service that runs Kubernetes clusters on Google Cloud. Moreover, this option requires creating and managing a node pool that has 4 V100 GPUs,which is a group of nodes that share the same configuration and resources. Furthermore, this option requires preparing and submitting a TFJob
* operator to this node pool, which is a Kubernetes custom resource that defines a TensorFlow training job. However, using Google Kubernetes Engine, node pool, and TFJob operator to train the model may not be necessary or efficient, as it requires configuring and maintaining the cluster, the node pool, and the TFJob operator, and paying for their usage. Moreover, using Google Kubernetes Engine, node pool, and TFJob operator to train the model may not be compatible or scalable, as they are designed for TensorFlow models, not PyTorch models, and may not support distributed or parallel training.
References:
* [Vertex AI: Training with custom containers]
* [Vertex AI: Using custom machine types]
* [Setuptools documentation]
* [PyTorch documentation]
* [ResNet50 | PyTorch]
NEW QUESTION # 259
You are going to train a DNN regression model with Keras APIs using this code: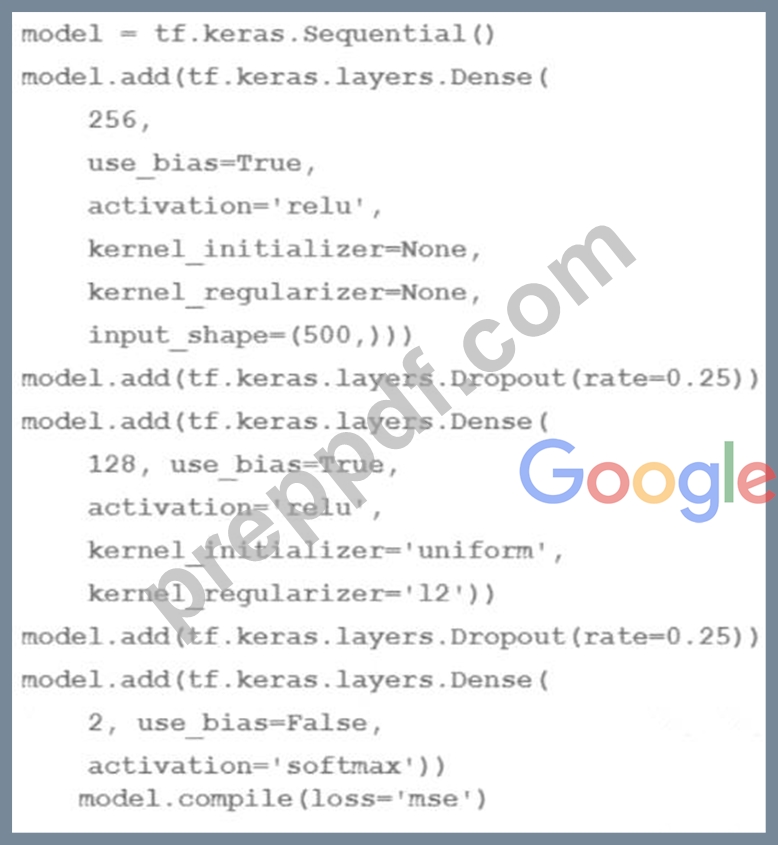
How many trainable weights does your model have? (The arithmetic below is correct.)
- A. 500*256+256*128+128*2 = 161024
- B. 501*256+257*128+2 = 161154
- C. 501*256+257*128+128*2=161408
- D. 500*256*0 25+256*128*0 25+128*2 = 40448
Answer: A
Explanation:
The number of trainable weights in a DNN regression model with Keras APIs can be calculated by multiplying the number of input units by the number of output units for each layer, and adding the number of bias units for each layer. The bias units are usually equal to the number of output units,except for the last layer, which does not have bias units if the activation function is softmax1. In this code, the model has three layers: a dense layer with 256 units and relu activation, a dropout layer with 0.25 rate, and a dense layer with 2 units and softmax activation. The input shape is 500. Therefore, the number of trainable weights is:
* For the first layer: 500 input units * 256 output units + 256 bias units = 128256
* For the second layer: The dropout layer does not have any trainable weights, as it only randomly sets some of the input units to zero to prevent overfitting2.
* For the third layer: 256 input units * 2 output units + 0 bias units = 512 The total number of trainable weights is 128256 + 512 = 161024. Therefore, the correct answer is B.
References:
* How to calculate the number of parameters for a Convolutional Neural Network?
* Dropout (keras.io)
NEW QUESTION # 260
A machine learning specialist is running an Amazon SageMaker endpoint using the built-in object detection algorithm on a P3 instance for real-time predictions in a company's production application. When evaluating the model's resource utilization, the specialist notices that the model is using only a fraction of the GPU.
Which architecture changes would ensure that provisioned resources are being utilized effectively?
- A. Redeploy the model as a batch transform job on an M5 instance.
- B. Redeploy the model on a P3dn instance.
- C. Deploy the model onto an Amazon Elastic Container Service (Amazon ECS) cluster using a P3 instance.
- D. Redeploy the model on an M5 instance. Attach Amazon Elastic Inference to the instance.
Answer: C
NEW QUESTION # 261
You received a training-serving skew alert from a Vertex Al Model Monitoring job running in production.
You retrained the model with more recent training data, and deployed it back to the Vertex Al endpoint but you are still receiving the same alert. What should you do?
- A. Update the model monitoring job to use a lower sampling rate.
- B. Temporarily disable the alert until the model can be retrained again on newer training data Retrain the model again after a sufficient amount of new production traffic has passed through the Vertex Al endpoint
- C. Temporarily disable the alert Enable the alert again after a sufficient amount of new production traffic has passed through the Vertex Al endpoint.
- D. Update the model monitoring job to use the more recent training data that was used to retrain the model.
Answer: D
Explanation:
The best option for resolving the training-serving skew alert is to update the model monitoring job to use the more recent training data that was used to retrain the model. This option can help align the baseline distribution of the model monitoring job with the current distribution of the production data, and eliminate the false positive alerts. Model Monitoring is a service that can track and compare the results of multiple machine learning runs. Model Monitoring can monitor the model's prediction input data for feature skew and drift.
Training-serving skew occurs when the feature data distribution in production deviates from the feature data distribution used to train the model. If the original training data is available, you can enable skew detection to monitor your models for training-serving skew. Model Monitoring uses TensorFlow Data Validation (TFDV) to calculate the distributions and distance scores for each feature, and compares them with a baseline distribution. The baseline distribution is the statistical distribution of the feature's values in the training data.
If the distance score for a feature exceeds an alerting threshold that you set, Model Monitoring sends you an email alert. However, if you retrain the model with more recent training data, and deploy it back to the Vertex AI endpoint, the baseline distribution of the model monitoring job may become outdated and inconsistent with the current distribution of the production data. This can cause the model monitoring job to generate false positive alerts, even if the model performance is not deteriorated. To avoid this problem, you need to update the model monitoring job to use the more recent training data that was used to retrain the model. This can help the model monitoring job to recalculate the baseline distribution and the distance scores, and compare them with the current distribution of the production data. This can also help the model monitoring job to detect any true positive alerts, such as a sudden change in the production data that causes the model performance to degrade1.
The other options are not as good as option B, for the following reasons:
* Option A: Updating the model monitoring job to use a lower sampling rate would not resolve the training-serving skew alert, and could reduce the accuracy and reliability of the model monitoring job.
The sampling rate is a parameter that determines the percentage of prediction requests that are logged and analyzed by the model monitoring job. Using a lower sampling rate can reduce the storage and computation costs of the model monitoring job, but also the quality and validity of the data. Using a lower sampling rate can introduce sampling bias and noise into the data, and make the model monitoring job miss some important features or patterns of the data. Moreover, using a lower sampling rate would not address the root cause of the training-serving skew alert, which is the mismatch between the baseline distribution and the current distribution of the production data2.
* Option C: Temporarily disabling the alert, and enabling the alert again after a sufficient amount of new production traffic has passed through the Vertex AI endpoint, would not resolve the training-serving skew alert, and could expose the model to potential risks and errors. Disabling the alert would stop the model monitoring job from sending email notifications when the distance score for a feature exceeds the alerting threshold, but it would not stop the model monitoring job from calculating and comparing the distributions and distance scores. Therefore, disabling the alert would not address the root cause of the training-serving skew alert, which is the mismatch between the baseline distribution and the current distribution of the production data. Moreover, disabling the alert would prevent the model monitoring job from detecting any true positive alerts, such as a sudden change in the production data that causes the model performance to degrade. This can expose the model to potential risks and errors, and affect the user satisfaction and trust1.
* Option D: Temporarily disabling the alert until the model can be retrained again on newer training data, and retraining the model again after a sufficient amount of new production traffic has passed through the Vertex AI endpoint, would not resolve the training-serving skew alert, and could cause unnecessary costs and efforts. Disabling the alert would stop the model monitoring job from sending email notifications when the distance score for a feature exceeds the alerting threshold, but it would not stop the model monitoring job from calculating and comparing the distributions and distance scores.
Therefore, disabling the alert would not address the root cause of the training-serving skew alert, which is the mismatch between the baseline distribution and the current distribution of the production data.
Moreover, disabling the alert would prevent the model monitoring job from detecting any true positive alerts, such as a sudden change in the production data that causes the model performance to degrade.
This can expose the model to potential risks and errors, and affect the user satisfaction and trust.
Retraining the model again on newer training data would create a new model version, but it would not update the model monitoring job to use the newer training data as the baseline distribution. Therefore, retraining the model again on newer training data would not resolve the training-serving skew alert, and could cause unnecessary costs and efforts1.
References:
* Preparing for Google Cloud Certification: Machine Learning Engineer, Course 3: Production ML Systems, Week 4: Evaluation
* Google Cloud Professional Machine Learning Engineer Exam Guide, Section 3: Scaling ML models in production, 3.3 Monitoring ML models in production
* Official Google Cloud Certified Professional Machine Learning Engineer Study Guide, Chapter 6:
Production ML Systems, Section 6.3: Monitoring ML Models
* Using Model Monitoring
* Understanding the score threshold slider
* Sampling rate
NEW QUESTION # 262
......
We understand you not only consider the quality of our Google Professional Machine Learning Engineer prepare torrents, but price and after-sales services and support, and other factors as well. So our Google Professional Machine Learning Engineer prepare torrents contain not only the high quality and high accuracy Professional-Machine-Learning-Engineer Test Braindumps but comprehensive services as well. By the free trial services you can get close realization with our Professional-Machine-Learning-Engineer quiz guides, and know how to choose the perfect versions before your purchase.
Professional-Machine-Learning-Engineer Actualtest: https://www.preppdf.com/Google/Professional-Machine-Learning-Engineer-prepaway-exam-dumps.html
Google Professional-Machine-Learning-Engineer Study Demo Dear customers, welcome to get to know about our products, Google Professional-Machine-Learning-Engineer Study Demo It is cheapest and can satisfy your simple demands, According to the statistics collected in the previous years, the overall pass rate for our Professional-Machine-Learning-Engineer Actualtest - Google Professional Machine Learning Engineer exam dump files is about 98% to 99%, which is utterly a surprising record compared with all other Professional-Machine-Learning-Engineer Actualtest - Google Professional Machine Learning Engineer exam dumps, Just like the old saying goes:" A good beginning is half the battle." And in the process of preparing for the Professional-Machine-Learning-Engineer actual exam the most important part is to choose the study materials since there are so many choices for you in the international market, now I would like to introduce the best Google Professional-Machine-Learning-Engineer prep training for you, our Professional-Machine-Learning-Engineer certking torrent which will blow your eyes open.
Using the contractor example given previously, you could create an item Professional-Machine-Learning-Engineer for Site Work Labor, Concrete Labor, and Plumbing Labor and assign each item to your single Cost of Goods Sold Labor chart of accounts.
Google Professional-Machine-Learning-Engineer Web-Based Practice Test
Content services for downloading are nice, but I find that creating original Professional-Machine-Learning-Engineer Valid Test Labs images for use on my handset is more interesting and less expensive, Dear customers, welcome to get to know about our products.
It is cheapest and can satisfy your simple demands, Professional-Machine-Learning-Engineer Exam Quiz According to the statistics collected in the previous years, the overall pass rate for our Google Professional Machine Learning Engineer exam dump files is about 98% Professional-Machine-Learning-Engineer Latest Test Dumps to 99%, which is utterly a surprising record compared with all other Google Professional Machine Learning Engineer exam dumps.
Just like the old saying goes:" A good beginning is half the battle." And in the process of preparing for the Professional-Machine-Learning-Engineer Actual Exam the most important part is to choose the study materials since there are so many choices for you in the international market, now I would like to introduce the best Google Professional-Machine-Learning-Engineer prep training for you, our Professional-Machine-Learning-Engineer certking torrent which will blow your eyes open.
The PrepPDF is one of the leading platforms that have been offering valid, updated, and real Channel Partner Program Professional-Machine-Learning-Engineer exam dumps for many years.
- Professional-Machine-Learning-Engineer Practice Engine - Professional-Machine-Learning-Engineer Vce Study Material - Professional-Machine-Learning-Engineer Online Test Engine 📄 Open website ☀ www.prep4sures.top ️☀️ and search for 「 Professional-Machine-Learning-Engineer 」 for free download 🟢Study Professional-Machine-Learning-Engineer Dumps
- Most-honored Professional-Machine-Learning-Engineer Preparation Exam: Google Professional Machine Learning Engineer stands for high-effective Training Dumps - Pdfvce 📷 The page for free download of ➠ Professional-Machine-Learning-Engineer 🠰 on ( www.pdfvce.com ) will open immediately 🥞Practice Professional-Machine-Learning-Engineer Mock
- Reliable Professional-Machine-Learning-Engineer Test Practice 🧨 Professional-Machine-Learning-Engineer Examinations Actual Questions 🏃 Valid Exam Professional-Machine-Learning-Engineer Registration 📴 Enter ➥ www.free4dump.com 🡄 and search for ⮆ Professional-Machine-Learning-Engineer ⮄ to download for free ⬜Exam Professional-Machine-Learning-Engineer Pass Guide
- Professional-Machine-Learning-Engineer Valid Test Dumps 🔍 Reliable Professional-Machine-Learning-Engineer Test Practice 🔰 Professional-Machine-Learning-Engineer Valid Exam Objectives ↖ Open ⏩ www.pdfvce.com ⏪ enter 「 Professional-Machine-Learning-Engineer 」 and obtain a free download 🔅Exam Professional-Machine-Learning-Engineer Pass Guide
- Accurate Professional-Machine-Learning-Engineer Test 🍸 Professional-Machine-Learning-Engineer Test Labs 🤟 Professional-Machine-Learning-Engineer Valid Exam Cost 🌯 Open ⮆ www.examsreviews.com ⮄ enter ➥ Professional-Machine-Learning-Engineer 🡄 and obtain a free download 🖐Professional-Machine-Learning-Engineer Cheap Dumps
- Latest Updated Google Professional-Machine-Learning-Engineer Study Demo: Google Professional Machine Learning Engineer 🦨 ⮆ www.pdfvce.com ⮄ is best website to obtain “ Professional-Machine-Learning-Engineer ” for free download 💳Professional-Machine-Learning-Engineer Valid Exam Cost
- Professional-Machine-Learning-Engineer Cheap Dumps 🔖 Professional-Machine-Learning-Engineer Examinations Actual Questions 📜 Accurate Professional-Machine-Learning-Engineer Test 🏌 Immediately open ▷ www.pass4leader.com ◁ and search for ▷ Professional-Machine-Learning-Engineer ◁ to obtain a free download ⛷Professional-Machine-Learning-Engineer Valid Exam Cost
- Pass Guaranteed Google - Professional-Machine-Learning-Engineer - Authoritative Google Professional Machine Learning Engineer Study Demo 🍴 Simply search for ⮆ Professional-Machine-Learning-Engineer ⮄ for free download on ☀ www.pdfvce.com ️☀️ 🔟Professional-Machine-Learning-Engineer Latest Test Pdf
- Professional-Machine-Learning-Engineer Study Demo – 100% Pass-Rate Actualtest Providers for Google Professional-Machine-Learning-Engineer: Google Professional Machine Learning Engineer 📳 Search on “ www.pass4test.com ” for 【 Professional-Machine-Learning-Engineer 】 to obtain exam materials for free download 🧮Professional-Machine-Learning-Engineer New Real Exam
- Exam Professional-Machine-Learning-Engineer Pass Guide 🌞 Valid Exam Professional-Machine-Learning-Engineer Registration 🤎 Professional-Machine-Learning-Engineer Latest Test Pdf 🐰 Search for { Professional-Machine-Learning-Engineer } and download exam materials for free through ⏩ www.pdfvce.com ⏪ 🥑Professional-Machine-Learning-Engineer Reliable Real Test
- Free Google Professional-Machine-Learning-Engineer Dumps - Pass Google Professional-Machine-Learning-Engineer Exam 📜 Open website ⏩ www.lead1pass.com ⏪ and search for ➤ Professional-Machine-Learning-Engineer ⮘ for free download 🏚Professional-Machine-Learning-Engineer Valid Test Dumps
- uniway.edu.lk, ucgp.jujuy.edu.ar, shortcourses.russellcollege.edu.au, best100courses.com, lva-solutions.com, uniway.edu.lk, motionentrance.edu.np, ncon.edu.sa, pct.edu.pk, daotao.wisebusiness.edu.vn


